РОССИЙСКО – АРМЯНСКИЙ (СЛАВЯНСКИЙ) ГОС. УНИВЕРСИТЕТ
КУРСОВАЯ РАБОТА
Тема «Рекуррентный многослойный персептрон».
Руководитель: Баградян В.Г.
Исполнитель: Алексанян А.С.
ЕРЕВАН – 2004 г.
Введение
Персептрон – это перцептрон ( от латинского perceptio – понемание, познование, восприятие), математическая модель процесса восприятия. Сталкивясь с новыми явлениями или предметми, человек их узнаёт, т.е. относит к тому или иному понятию (т.е. к классу). Эта способность человека и получила название феномена восприятия. Человек умеет на основании опыта вырабатывать и новые понятия, обучаться новым системам классификации. Например, при обучении различению рукописных знаков ученику показывют рукописные знаки и сообщают, каким буквам они соответствуют, т.е. к кким классам эти знаки относятся. В результате у него вырабатывается умение првильно классифицировать знаки.
Восприятие осуществляется припомощи сети нейронов. Модель восприятия (персептивная модель) может быть представлена в виде трёх слоёв нейронов: рецептивного слоя (NI), слоя преобразующих нейронов (NH) и слоя реагирующих нейронов (No).
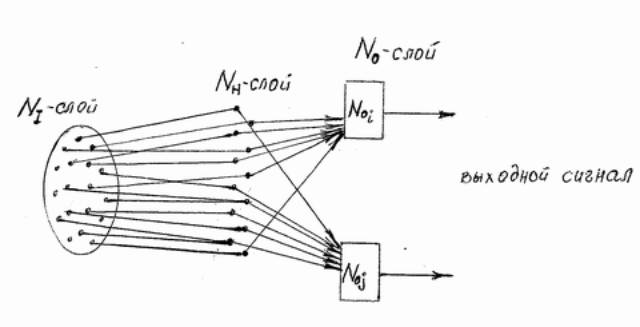
Нейрон (соглсно наиболее простой модели Мак – Каллока – Пирса) – это нервная клетка, которая имеет несколько входов и один выход. Входы могут быть либо возбуждающие, либо тормозные. Нейрон возбуждается и посылет импульс в том случае, если количество сигналов на возбуждающих входах превосходит число сигналов на тормозных входах на некоторую величину, называемую порогом сбрасывания нейрона.
В звисимости от характера внешнего раздражения в NI – слое образуется некая совокупность импульсов (сигнлов), которые расспространяясь по нервным путям, достигают нейронов NH – слоя , где в соответствии с совокупностью пришедших импульсов образуются новые импульсы, поступающие на входы нейронов No – слоя. В нейронах NH – слоя суммируются входные сигналы с одним и тем же коэффициентом усиления (возможно с разными знаками), в нейронах же No – слоя суммируются сигналы с различными как по величине, так и по знаку коэффициента.
Считают, что коэффициенты усиления реагирующих нейронов подобраны так, что различным объектам одного класса соответствуют совокупности импульсов , возбуждающие один и тот же нейрон No – слоя. Формирование нового понятия заключется в установлении коэффициента усиления соответствующего реагирующего нейрона.
Математическое исследование персептронных схем связано с здачей обучения распозновнию образов, где выясняется, как должна быть построена преобразующая часть и каков алгоритм установления коэффициентов усиления No – элементов в режиме обучения.
Рекуррентный многослойный персептрон (RMPL).
Перед тем как перейти к структуре сети RMLP, поймём сперва, что такое многослойный персептрон.
Нейроны могут объединяться в сети различным образом. Самым рспространённым видом сети стал многослойный персептрон.
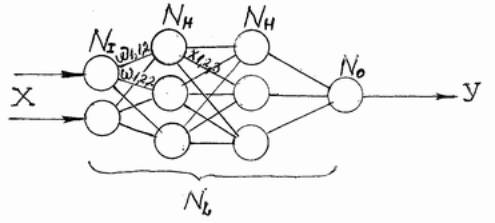
Сеть состоит из произвольного числа нейронов. Нейроны каждого слоя соединяются с нейронами предидущего и последующего слоёв по принципу «каждый с каждым». Первый слой (слев) называется входным, внутренние слои называются скрытыми, последний (самый правый, из одного нейрона) – выходным. Количество нейронов в слоях может быть произвольным. Обычно во всех скрытых слоях одинковое количество нейронов.
Обозначим количество слоёв и нейронов в слое. Входной слой NI нейронов; NH нейронов в каждом скрытом слое; No выходных нейронов. Х – вектор входных сигналов, Y – вектор входных сигналов.
Существует путаница с подсчётом количества слоёв в сети. Входной слой не выполняет никаких вычислений, а лишь распределяет входные сигналы, поэтому иногда его считают, иногда – нет.
Оюозначим через NL полное количество слоёв в сети, считая входной.
Работа многослойного персептрона описывается формулами:
NETjl =Swijlxijl
OUTjl = F(NETjl - qjl)
xjl (l+1) = OUTil ,
где индексом i всегда будем обозначать номер входа, j – номер нейрона в слое, l – номер слоя.
xijl – i –й входной сигнал j – го нейрона в слое l;
wijl – весовой коэффициент i – го входа нейрона номер j в слое l;
NETjl – сигнал NET j – го нейрона в слое l;
OUTjl – выходной сигнал нейрона;
qjl – пороговый уровень нейрона j в слое l;
Введём обозначения: wjl – вектор – столбец весов для всех входов нейрона j в слое l; wl – матрица весов всех нейронов в слое l. В столбцах матрицы расположены вектора wjl. Анологично xjl – выходной вектор – столбец слоя l.
Каждый слой рассчитывает нелинейное преобразование от линейной комбинации сигналов предидущего слоя. Отсюда видно, что линейная функция активации может применяться только для тех моделей сетей, где не требуется последовательное соединение слоёв нейронов друг за другом. Для многослойных сетей функция активации должна быть нелинейной, иначе можно построить эквивалентную однослойную сеть, и многослойность оказывается ненужной. Если применен линейная функция активации, то каждый слой будет давать на выходе линейную комбинацию входов. Следующий слой даст линейную комбинацию выходов предидущего, а это эквивалентно одной линейной комбинации с другими коэффициентами, и может быть реализовано в виде одного слоя нейронов.
Персептронная сеть с обратной связью.
Один из простейших способов построения рекуррентной ИНС состоит во введении в персептронную сеть обртной связи.
В дальнейшем мы будем сокращённо называть такую сеть RMLP ( Recurrent MultiLayer Perceptron). Для выполнения последующих рассчётов введём новые обозначения элементов сети. Её обобщённая структура представляется так:

Рис.: Структура сети RMLP.
Это динамическая сеть, характеризующяся запаздывнием входных и выходных сигналов, объединяемых во входной вектор сети. Рассуждения косаютя узла x(k) и одного выходного нейрона, также одного скрытого слоя. Такая система реализует отобржение:
y(k+1) = f(x(k), x(k-1), …, x(k-(N-1)), y(k-1), y(k-2), …, y(k-P)), (1)
где N-1 – количество зодержек входного сигнала, а P – количество зодержек выходного сигнала.
Обозначим K количество нейронов в скрытом слое. В этом случае сеть RMPL можно характеризовать тройкой чисел (N,P,K). Подаваемый на вход сети вектор x имеет вид:
x(k) = [1, x(k), x(k-1), …, x(k-(N-1)), y(k-P), y(k-P+1), …, y(k-1)]T.
Допостим, что все нейроны имеют сигмаидальную функцию активации. Обозначим ui взвешенную сумму сигналов i – го нейрона скрытого слоя, а g – взвешенную сумму сигналов входного нейрона. Тогда мы получим:
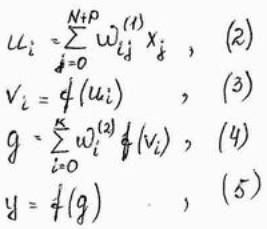
Алгоритм обучения сети RMLP.
Сеть RMLP адаптируется с применением градиентного алгоритма обучения. Рассчитывется градиент целевой функции относительно каждого веса. Для упращения будем рассматривать сеть с одним выходным нейроном. В этом случае целевя функция в момент t может определить в виде
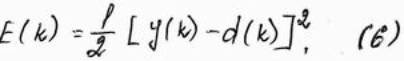
Дифференцируя эту функцию относительно произвольного веса wa(2) (a = 0,1, …, k) выходного слоя сети, получем:
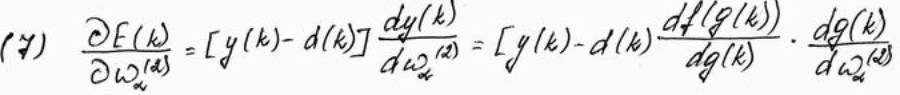
С учётом зависимостей (2) – (5)
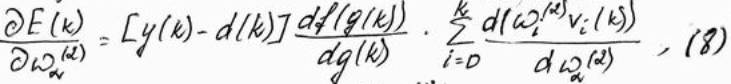
где vi = f(ui).
Производная 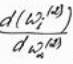 равна 1 только при i = a и равна 0 во всех остальных случаях.
равна 1 только при i = a и равна 0 во всех остальных случаях.
Тогда
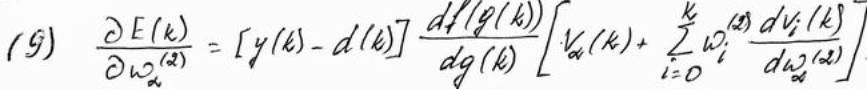 ,
,
причём
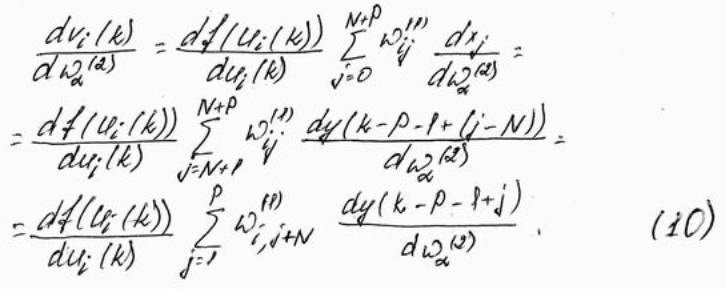 .
.
С учётом зависимостей (6) – (10) получим
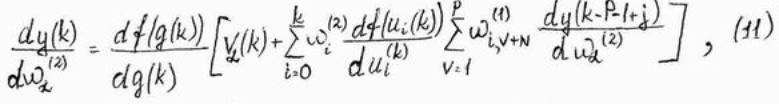
Рекуррентная формула (11) позволяет рассчитать значение производной dy(k)/dwa(2) в произвольный момент времени по её значениям в предидущие моменты. Она связывает значения производных в момент t со значениями тех же функций в моменты t-1, t-2, …, t-P. Можно предположить, что начльные значения производных от сигналов перед началом обучения равны, т.е.
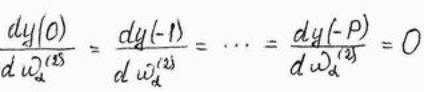
При использовнии в процессе обучения метода наискорейшего спуска адаптация весов выходного слоя определяется формулой
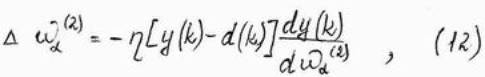
Актуализация весов скрытого слоя происходит аналогичным образом. После расчёта производной сигнала y(k) относительно веса wa,bb(1) скрытого слоя получем
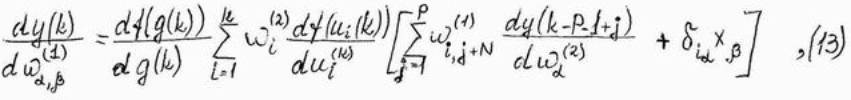
Следовательно, формула, определяющая адаптацию веса wa,bb(1) скрытого слоя, при использовании метода наискорейшего спуска принимает вид
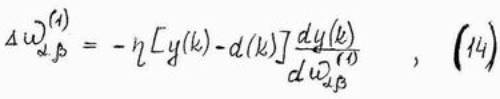
В конечном виде алгоритм обучения сети RMLP является:
1. Выполнить инициализацию случайным образом весов нейронов скрытого и выходного слоёв.
2. Для кждого момента t при заданном возбуждении в виде вектора x рассчитать состояние всех нейронов сети в соответствии с формулами (2) – (5).
3. С помощью зависимостей (11) и (13) определить значение производных dy(k)/dwa(2) и dy(k)/dwab(1) для всех значений a и b,соответствующих весам сети из изначально выбранной структурой.
4. Актуализировать веса в соответствии с формулами (12) и (14), после чего вернуться в п.2 настоящего алгоритма.
Предствленный алгоритм функционирует «онлайн», принимая поступающие входные данные и соответствующие им значения ожидаемого вектора d и оперативно корректируя знчения весов.
При обучении нейронной сети по методу обратного распространения ошибок решающее влияние на скорость обучения и на получаемые конечные результаты оказывает коэффициент обучения h. Если обозначить ei-1 и ei погрешность адаптации на i – м и (i-1) – м шаге, а hi-1 и hi - соответствующие им коэффициенты обучения, то в случае ei>kwei-1 (kw – коэффициент допустимого прироста погрешности) производится уменьшение значения h по формуле
hi+1 = hi ad,
где ad является коэффициентом уменьшения значения h. В противном случае ei>kwei-1, значение этого коэффициента увеличивается по формуле
hi+1 = hi ai,
где ai является коэффициентом увеличения значения h.
И в заключение дадим описание проекта, написанного мною н C++: мы обучаем персептрон цифрам от 1 до 10(кроме нуля) и критерию чётности и нечётности. В ячейке Count мы набираем количество цифр, которым обучаем. В ячейке Signaly мы по очереди набираем те цифры, которым хотим обучить персептрон (порядок не важен). Когд задаётся более 10 цифр программа выдаёт предупреждение, что количество сигналов переполненно. После чего мы нажимаем на кнопку Obuchenie и по очереди выдаются в словесном виде все введённые числа, после чего разбиваются чётные и нечётные цифры соответственно в ячейках Kriterie Chotnosti и Kriterie nechotnosti.